
 Over the last 40 years, students and scholars have used WordCruncher to search, study, and analyze various digital texts ranging from the Dead Sea Scrolls to the Peanuts comics to baseball statistics. From time to time, we are asked by researchers if WordCruncher can perform a specific function or help speed up an analysis task. Recently we were asked whether WordCruncher had the ability to index word part of speech metadata. In the past we had employed a technique of tagging words with freeform part of speech information, but these techniques had limitations and were not universal across texts from different publishers. Since WordCruncher is actively supported by a development team in the Office of Digital Humanities, we can continue to add or change features to fit the needs of scholars.
Over the last 40 years, students and scholars have used WordCruncher to search, study, and analyze various digital texts ranging from the Dead Sea Scrolls to the Peanuts comics to baseball statistics. From time to time, we are asked by researchers if WordCruncher can perform a specific function or help speed up an analysis task. Recently we were asked whether WordCruncher had the ability to index word part of speech metadata. In the past we had employed a technique of tagging words with freeform part of speech information, but these techniques had limitations and were not universal across texts from different publishers. Since WordCruncher is actively supported by a development team in the Office of Digital Humanities, we can continue to add or change features to fit the needs of scholars.
Adding part of speech capabilities poses two problems: 1) analyzing the context of a text to determine each word’s part of speech and 2) indexing that information so further analysis could be performed. Part of speech taggers like SpaCy and Stanza are already prevalent to solve the first problem, so we focused on the latter. These various taggers will analyze the text and insert 3 or 4 letter mnemonic codes to define the parts of speech. However, the codes used by each tagger are specific to each program. Therefore, we decided to define our own universal system of tagging words and provided a simple mechanism to translate the tags created by the various taggers.
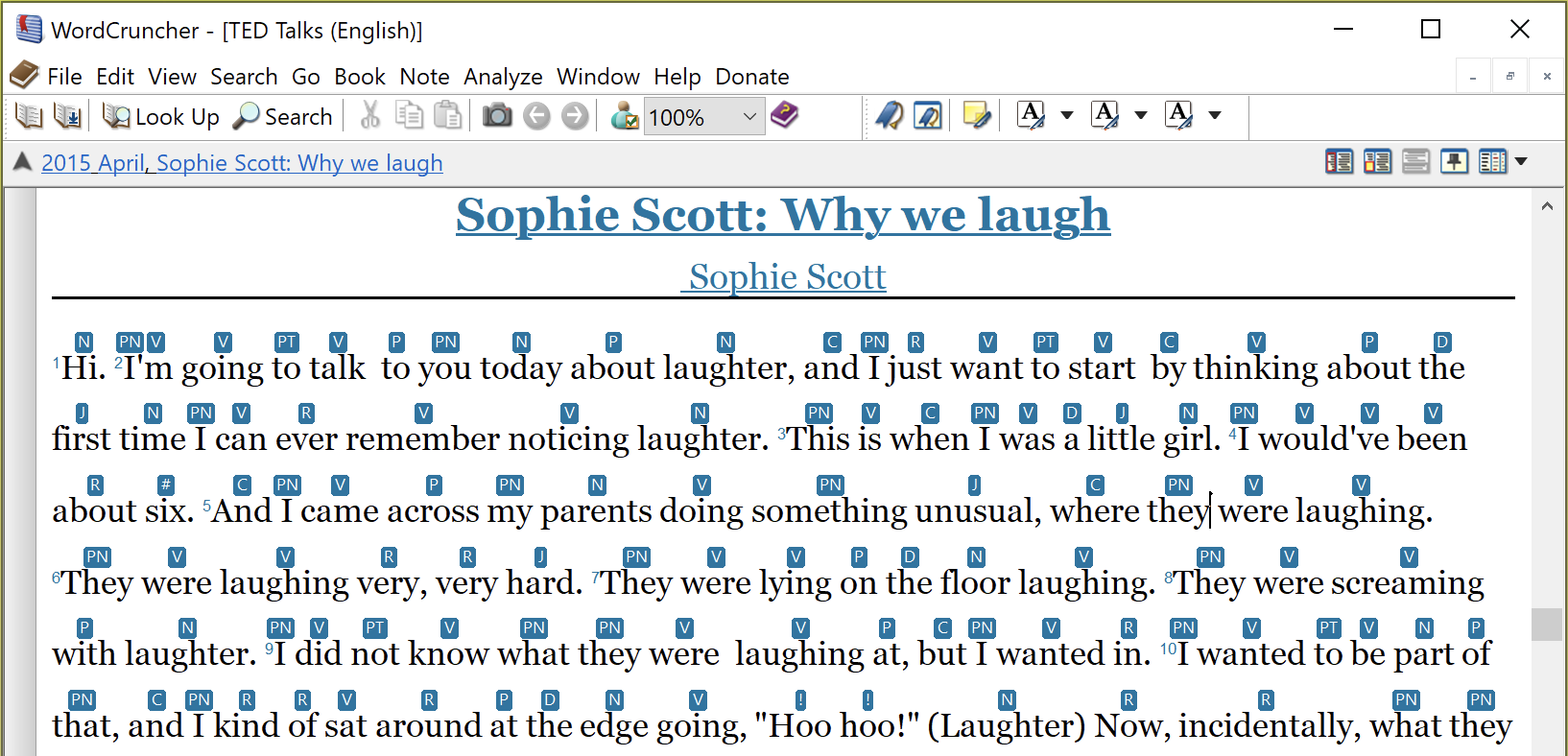
As a test of using parts of speech within WordCruncher, Jesse Vincent downloaded a collection of TED talks in several different languages. He used the Stanza tagger to add part of speech tags to the talks. When viewing one of these texts, the part of speech tags appear above each word in the text window. We provide several user options for customizing the display of these tags.
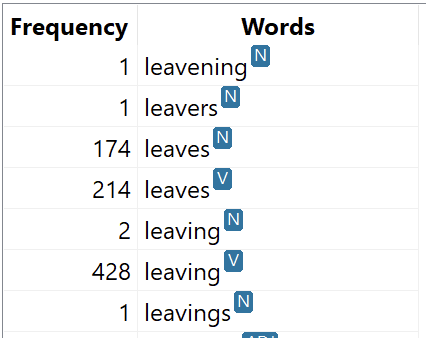 Words that are the same but have different parts of speech appear as separate entries on the WordWheel and can be searched individually. We also can search for the part of speech alone, e.g., find all the Nouns. We can then combine these simple queries into more complex ones to do further analysis of a text.
Words that are the same but have different parts of speech appear as separate entries on the WordWheel and can be searched individually. We also can search for the part of speech alone, e.g., find all the Nouns. We can then combine these simple queries into more complex ones to do further analysis of a text.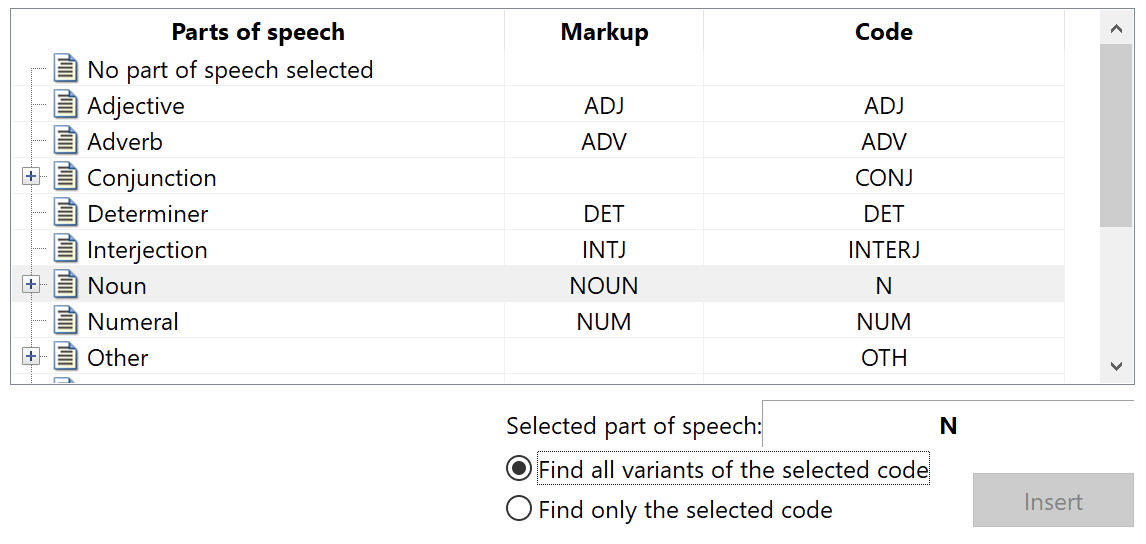
Part of speech information helps remove ambiguity from a search. For instance, if we wanted to search for the English word “leaves” as a verb, we can find that word in the WordWheel and select the variant marked as a verb. This query will ignore all instances where “leaves” is a noun and only return results it is used as a verb. WordCruncher can also use the part of speech information when using an expansion lexicon to search for the verb forms of “leave” instead of the noun forms of “leaf”.
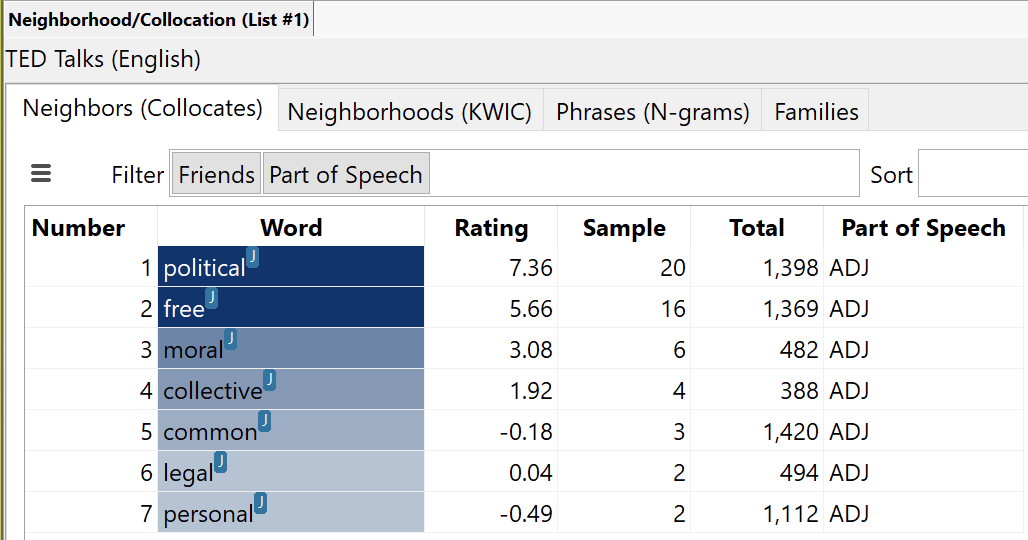 Another analysis tool that leverages part of speech information in WordCruncher is the Neighborhood (Collocation) Report. For example, if we search for the English word “will” as a noun and run the Neighborhood Report on the results we will be given a list of words that co-occur near the word “will”. This list can be further refined to filter out all the parts of speech of these co-occurring words except for adjectives. This allows the user to interpret only the adjectives that describe “will” and reveals that the words “political” and “free” occur with a high degree of significance near the word “will” where it is used as a noun. Of course, this may only be relevant for this particular corpus, but it is interesting none-the-less.
Another analysis tool that leverages part of speech information in WordCruncher is the Neighborhood (Collocation) Report. For example, if we search for the English word “will” as a noun and run the Neighborhood Report on the results we will be given a list of words that co-occur near the word “will”. This list can be further refined to filter out all the parts of speech of these co-occurring words except for adjectives. This allows the user to interpret only the adjectives that describe “will” and reveals that the words “political” and “free” occur with a high degree of significance near the word “will” where it is used as a noun. Of course, this may only be relevant for this particular corpus, but it is interesting none-the-less.
The inclusion of part of speech metadata as a native attachment to each word in the WordCruncher index has been a big improvement to the software and has increased its usefulness for students and scholars. This is just one example of how WordCruncher has become a collaborative effort of students, faculty, and software developers to help the scholarly community improve its research efforts. WordCruncher is a constantly evolving tool designed to enhance the search, study, and analysis of the written word.
Contact Jesse Vincent (or see webpage) to learn more about using WordCruncher to search, study, and analyze texts with part of speech tags, or to get help in adding part of speech tags to texts you are interested in.